现代数据库是一个复杂的系统工程,但是一个典型的数据库系统都是由固定的部分组成,本文以一条 SQL 的执行过程作为入口,对数据库系统的全貌进行一个简单介绍。
整体架构
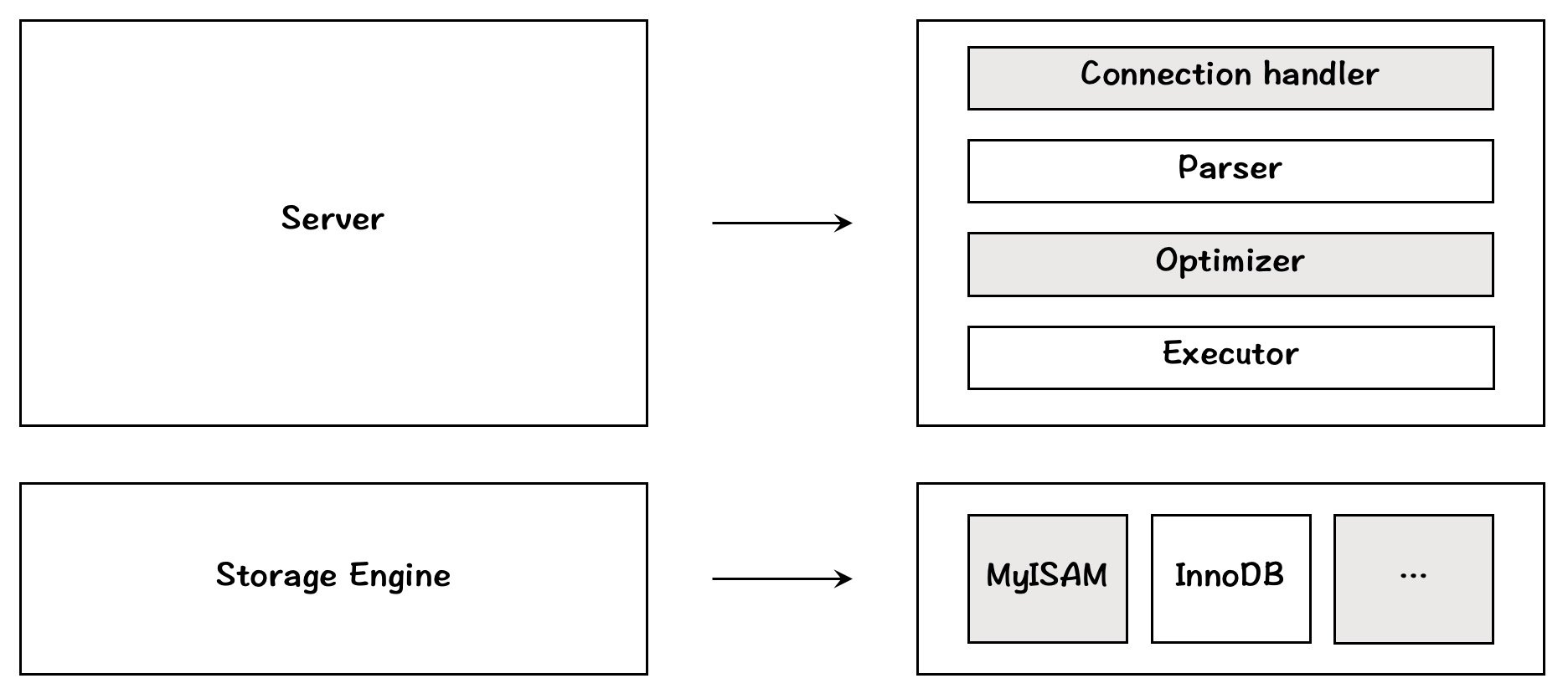
如图所示是一个关系型数据库系统的简单架构图,可以看到数据系系统是一个典型的 CS 架构。以 MySQL 为例,一个典型的数据库系统通常由两部分组成:Server 和 Storage Engine。Server 层按照功能划分又可以分为:连接处理(Connection handler)、语法解析(Parser)、优化器(Optimizer)、执行器(Executor)等部分。Storage Engine 也可以有不同的实现方式。
SQL 执行过程
还是以 MySQL 为例,介绍一条 SQL 的完整执行过程,其它关系型数据库的执行过程与 MySQL 基本类似。
连接处理
MySQL 客户端和服务端之间支持多种通信方式,除了最常用的 TCP 通讯外,还支持命名管道和共享内存的方式。以 TCP 通讯为例,MySQL 客户端与服务端的交互主要分为两个阶段:握手认证阶段和命令执行阶段。一次正常的连接过程如下:
1 | # 1. 建立 TCP 连接 |
其中,协议认证过程阶段就会对连接进行 ACL 认证,具体的认证过程和逻辑在此不作过多介绍,认证通过之后,就可以开始正式执行命令了。关于 MySQL 通讯协议的更多介绍,可以参考这篇文章。
语法解析
SQL 语法的设计也是数据库流行的一个重要原因,相比于传统的检索方式,SQL 语法可以说是相当的简单而且可读性高。SQL 语法有一个语法标准,但是各个数据库在实现的时候都会有自己的特点,以 MySQL 为例,MySQL 也只是兼容了部分 SQL 标准,对此社区有一个说明。
语法解析阶段其实包括了:词法分析和语法分析。当前最常用的语法解析方案是 LEX & YACC 的方案,这也是数据库系统里面用的最多的方案。MySQL 采用了一种比较有趣的组合,MySQL 并没有直接使用 LEX 作为词法分析的方案,而是手写了一套词法分析逻辑,但是语法分析依然采用了 YACC。关于 MySQL 语法解析的逻辑,后面会再写一篇文章来进行介绍。需要知道的是:语法解析过程会生成一棵语法树(Lex tree),原始 SQL 中的所有信息都会被记录在这棵树中。
注意:并不是所有的语句都需要经过语法解析的阶段,MySQL 内部实现了一套 Query Cache 机制,针对查询语句进行缓存,当缓存命中时,可以直接返回结果,此时不需要经过语法解析。
优化器
顾名思义,优化器的目的就是对用户的查询语句进行优化,找到一个合理的执行计划。之所以说是合理的执行计划,因为优化器本身并不保证所有的执行计划是最优的,而是尽量找到一个可以接受的执行计划。近些年,随着数据的膨胀和数据库本身的发展,对于优化器的研究也变得越来越热门,传统的 OLTP 型数据库也开始借鉴 OLAP 型数据库的优化思路。回到优化器本身,其要做的事情是:确定数据的读取方式和数据的计算方式。
一个最简单的例子,在使用数据库的过程中,当查询很慢的时候,DBA 首先会告诉你的就是:“看一下有没有有索引”。这里面索引的选择就是优化器的工作。
执行器
和优化器对应,执行器的工作是执行数据的读取和计算。和存储引擎的交互也都是在执行器内完成。在开始执行前,MySQL 会首先检查一下执行权限,如果没有对应表的权限,会直接返回没有权限的错误。如果有权限,则会根据表的引擎类型,按照优化器生成的执行计划,调用具体的接口进行处理。
存储引擎
MySQL 在设计之初就是一个支持多引擎的结构,MySQL 在执行器层定义了一个 handler 接口,接口内描述了所有执行器需要用到的基本操作,所有的存储引擎都需要实现相应的接口。常用的存储引擎包括:MyISAM、InnoDB、CSV、RocksDB等。多引擎的设计确实让 MySQL 拥有了很好的可扩展性,用户可以根据需要在表级指定存储引擎。但是随着 InnoDB 成为 MySQL 的默认引擎,特别是 8.0 版本开始使用 InnoDB 保存数据字典,这种多引擎的支持也会慢慢退出历史舞台。
以上结合数据库的基本架构简单介绍了一条 SQL 的执行过程,当然实际的执行过程远比这个复杂,后续会对各个部分展开说明。